From raw source
to cited answer.
One platform, five modules, no copies between systems. Click any module and go exactly as deep as you want — every design decision is documented.
01
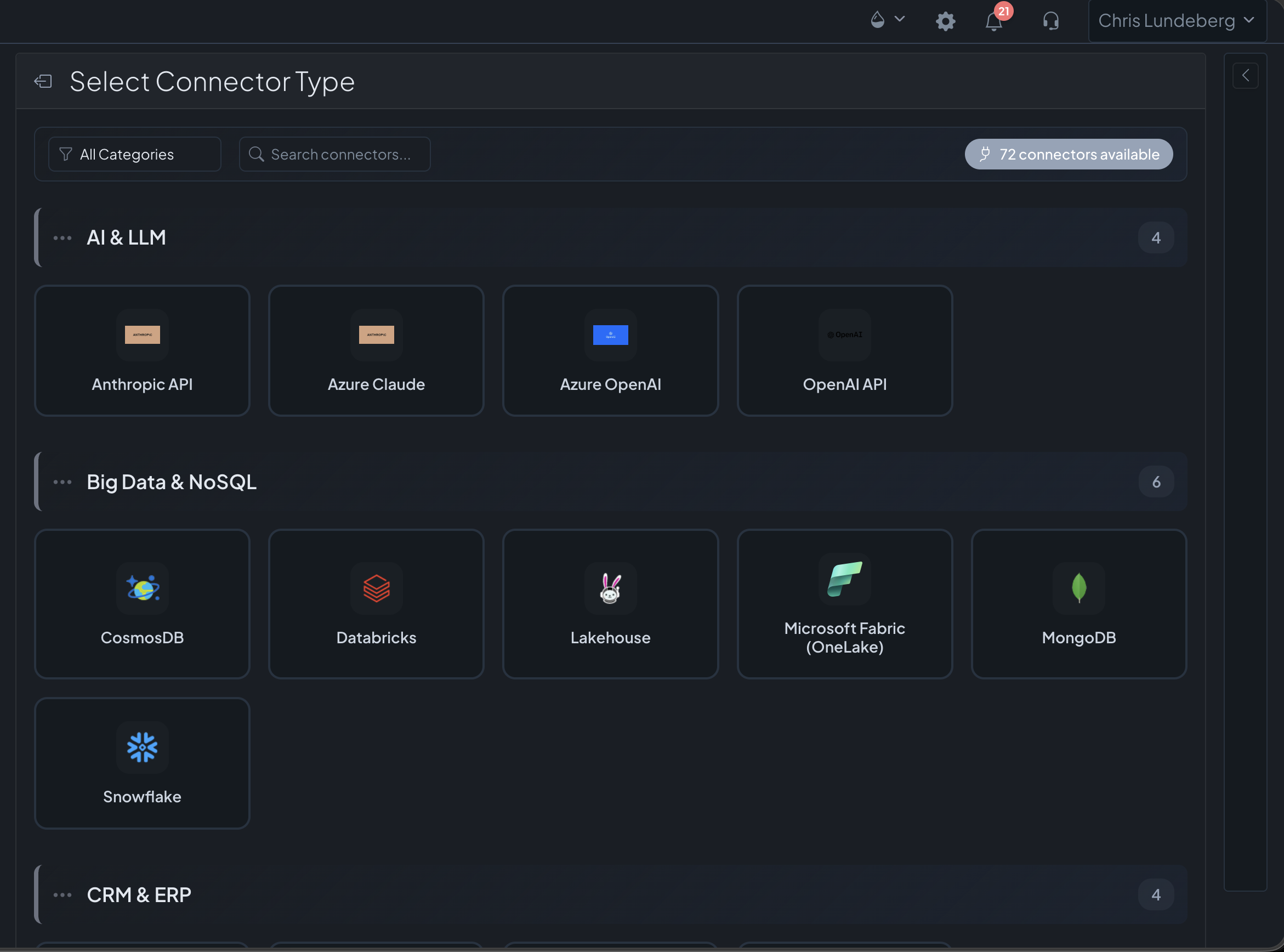
Connect: live sources & pipelinesQuery it now, or sync it for keeps — your call per source
Connect a supported source and it appears as live tables the moment credentials pass — SELECT * FROM live.hubspot.contacts runs directly against the API. First insight in minutes, zero pipeline, and your databases federate the same way. Built for exploration and quick answers.
One button builds the pipeline: schema mapped, schedule set, changes tracked. Data lands in your own lakehouse — full history, fast queries at any volume, and pre-built gold views for the 30 native sources. Built for speed, scale, and everything downstream.
Both lanes run on the same connector: schema-aware, probe-validated, built to understand the source's actual data model — the Epic connector knows Chronicles, Clarity, and Caboodle as distinct environments; the Workday connector resolves business objects and effective-date logic before your data ever lands.
Replaces CData · MuleSoft · Fivetran · custom API scripts
Live sources are rolling out across the native connectors now — the product shows you exactly which of your sources support live; everything supports sync. Browse all connectors →
02
Automate: the work engineSQL, dbt, notebooks, and AI agents — chained into stages
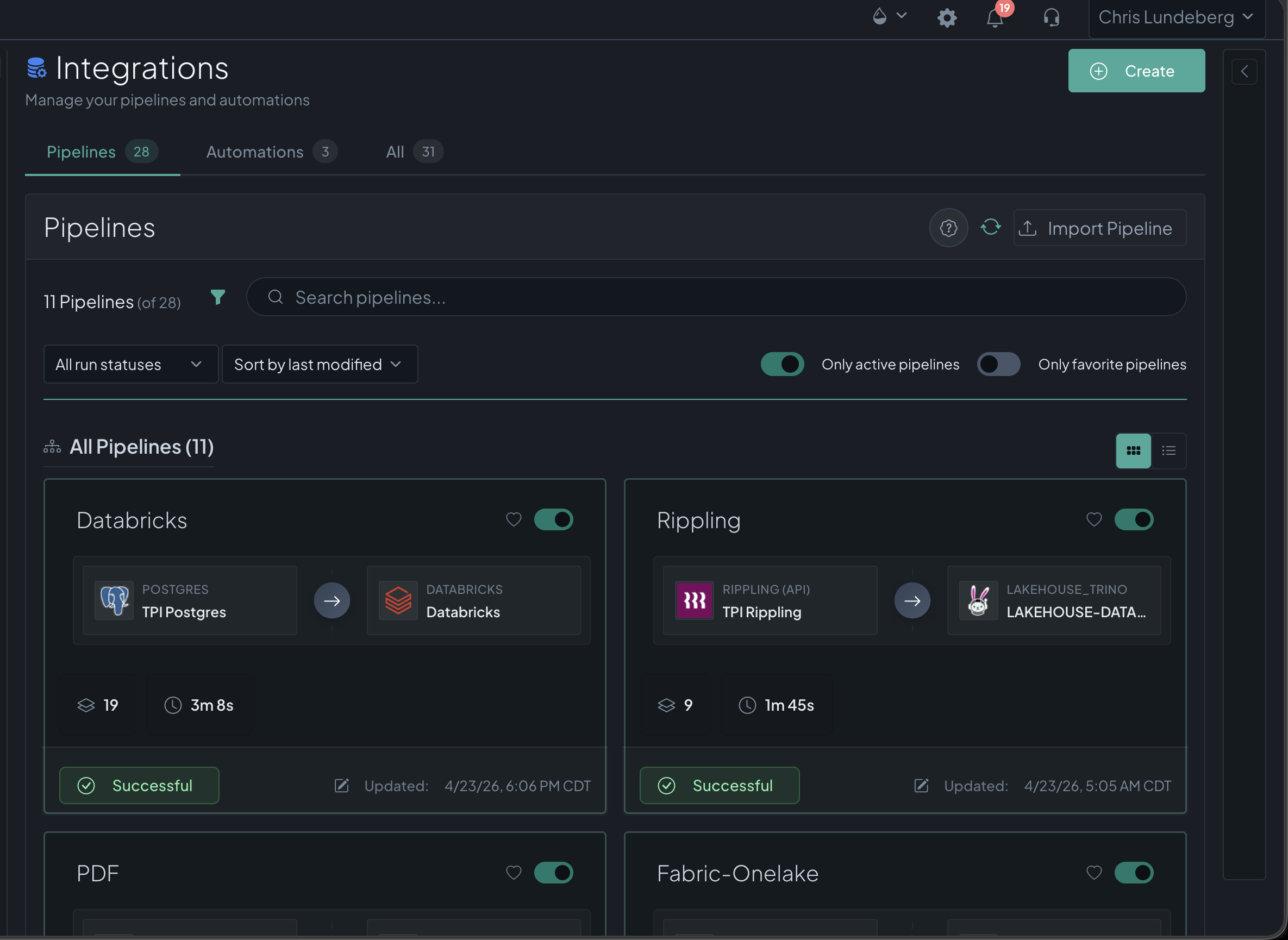
Connecting brings data in; Automations put it to work. A full orchestration engine built into the core, not a bolt-on: tasks chain into stages — tasks in the same stage run in parallel, stages run in order — and the whole board runs on a schedule or a trigger, with retries, per-task logs, and versioned snapshots of the automation itself.
Replaces Airflow / Dagster · dbt runners · Hightouch / Census · cron & scripts
03
Store & query: the open lakehouseApache Iceberg you own · Trino & Spark · zero copies
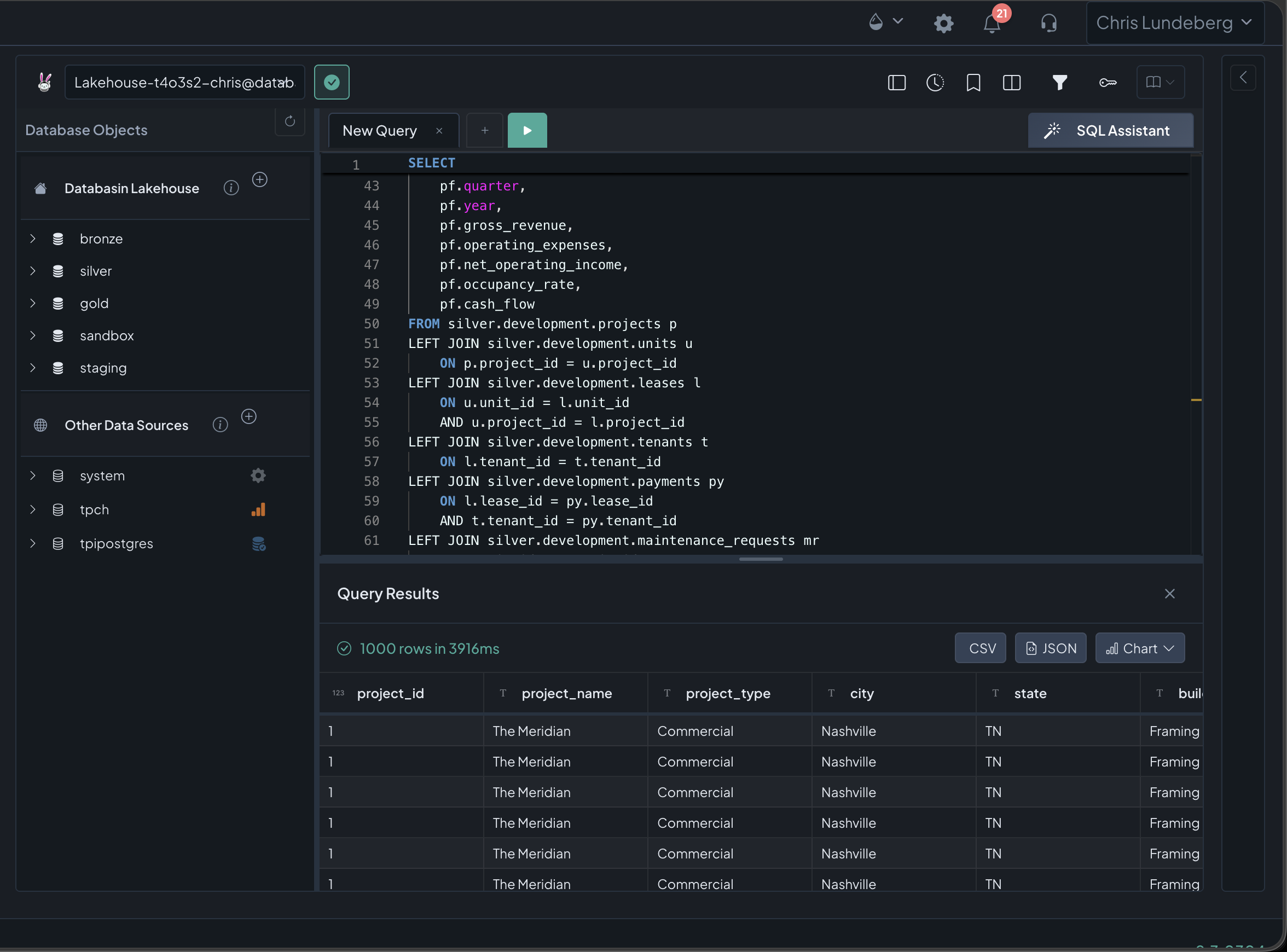
Synced data lives in Apache Iceberg — a vendor-neutral open format readable by any compatible engine, now and in the future. No exit tax, ever. Pipelines and automations move it through three governed tiers, and your gold layer is built from the questions you actually ask:
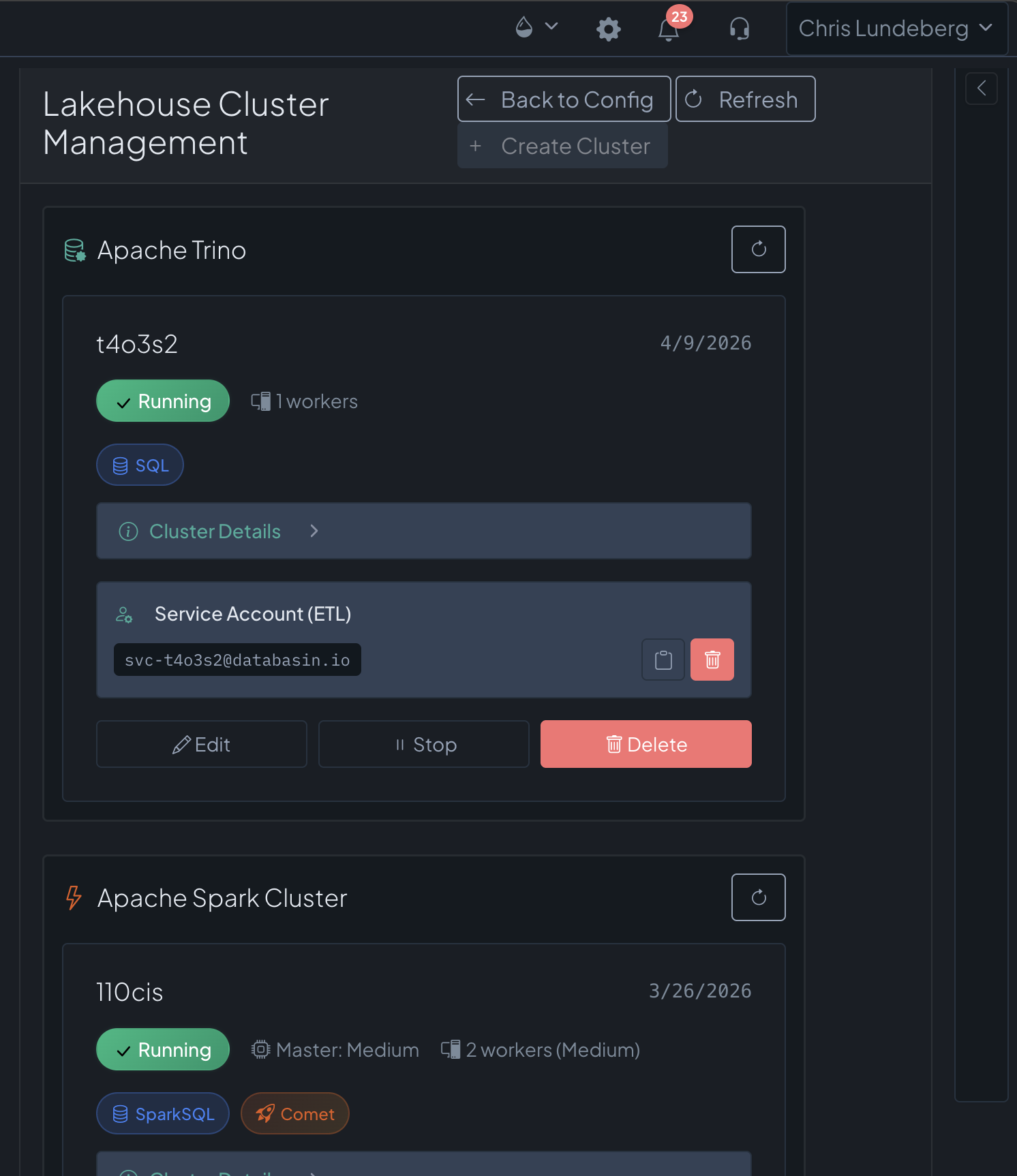
Two engines. One lake. Zero copies. Managed clusters bill per node-minute and cost nothing when stopped; access control runs per user, per catalog, per schema. And one Trino query can join it all — synced gold tables, live sources, and federated databases in a single statement.
Also in the toolbox: Apache Doris for sub-second, high-concurrency OLAP serving, DuckDB for in-process analytics — and BYO mode layers Databasin onto your existing Databricks, Snowflake, or Fabric instead of replacing it.
Replaces or overlays Snowflake · standalone Databricks · Azure Synapse · BigQuery
04
Ask: Databasin OneThe AI layer — answers with receipts, charts, documents, agents
The AI layer is architecturally constrained to your governed data — it can't hallucinate against raw tables because it never sees them. LLM-agnostic: GPT and Claude models via Azure OpenAI, or your internally approved model, running inside your security boundary. Governance and AI are built together, not bolted together.
Replaces Tableau · Power BI Premium · Looker · standalone AI API spend
05
Trust: governance & securityHIPAA-ready, encrypted, audited — trust by architecture
Databasin was co-created at Washington University School of Medicine, where the data was live, regulated PHI from day one. Security isn't a compliance checkbox layered on later — the architecture assumes the strictest posture and lets you relax it, not the reverse.
Every architectural decision has a reason.
Apache Iceberg — a vendor-neutral open format. Your data is readable by any compatible engine, now and in the future. No exit tax.
Sources, engines, agent skills, and destinations all plug in — and swap out — without re-platforming. Full stack or single module, your call.
Private install in your own Azure tenant when you need it. Your LLM, your endpoints, your governance rules. PHI never leaves your environment — by architecture, not by policy.
AI woven into the architecture, not bolted on. The AI layer queries governed gold data only — governed data in, trusted answers out.
See it applied to your environment.
HIPAA-ready by default.
Your security posture, your call.
Every deployment is encrypted, audited, and access-controlled. The hosted cloud is fully HIPAA-ready — most teams start there in five minutes. For the strictest PHI and data-residency needs, run the identical platform inside your own Azure tenant.
The fast path.
Fully managed and HIPAA-ready from day one. Sign up, click a connector, and you're querying in minutes — $50 in credit, no card.
Try it nowStrictest posture.
Install from the Azure Marketplace — the whole platform inside your walls. Your storage, your keys, your network, no data egress. Unlimited seats.
Talk to us about self-installCo-created at Washington University School of Medicine — built where the data was real, and regulated. Featured by Microsoft and Databricks at HIMSS '23, '24, and '25.
See it work on your own data.
The whole path you just read — running on your sources in five minutes.